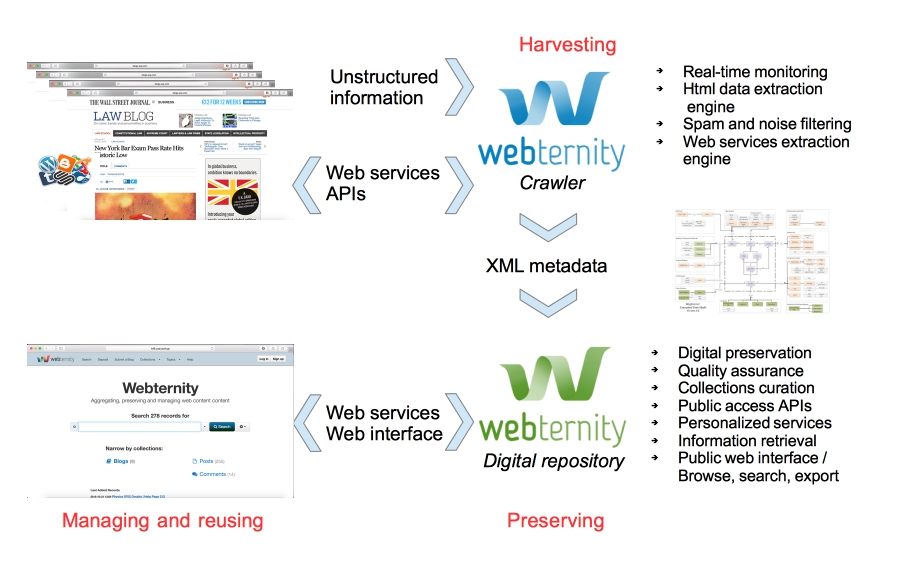
We have co-developed Webternity, an exciting web archiving system to harvest, preserve, manage and reuse web content. The system is performing an intelligent harvesting operation which retrieves and parses hypertext as well as all other associated content (images, linked files, etc.) from web and social media resources.
Our open source social media crawler is able to retrieve and structure websites and social media data on an unprecedented micro-level. Author names, comments, subjects, tags, categories, dates, links, and many other elements are expressed within a hierarchical structure.
This content is imported into the Webternity repository (based on CERN’s Invenio platform), a public-facing web archiving mechanism which provides facilities to preserve, view, interrogate and reuse the content to an unprecedented degree of detail.
Please let us know if you wish to receive more information.